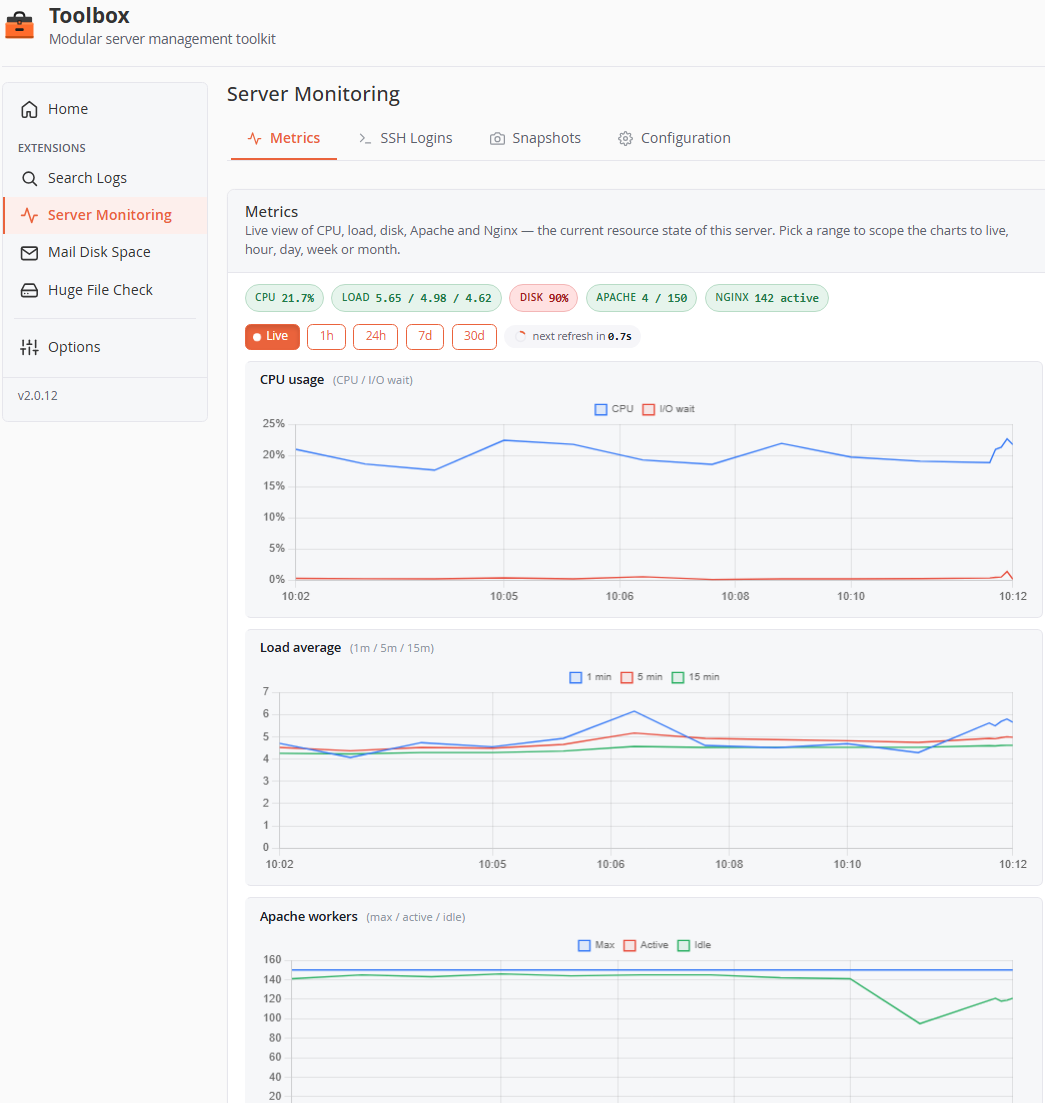
Live metrics, no daemon
One-minute samples of the numbers that matter, charted with your alert thresholds drawn right on the graphs. Pick a range from the last 10 minutes to 30 days.
- CPU and I/O wait, load average, disk per mount, Apache workers, Nginx connections
- Ranges: Live (auto-refresh), 1h, 24h, 7d, 30d
- Threshold + duration + cooldown alerting, emailed with a recovery notice
- Load thresholds are per-core, so one config works across every server